


Jun 9, 2024
Top 6 Techniques to Improve Query Performance and Load Data Faster in Databricks
In today's data-driven world, the ability to load data quickly and perform queries efficiently is paramount. This blog delves into the Top 6 Techniques to Improve Query Performance and Load Data Faster in Databricks. These strategies—Databricks Auto Loader, Data Skipping, Liquid Clustering, Predictive Optimization, Caching in Databricks, and Adaptive Query Execution—work together to enhance data loading and query performance. By the end, you'll see how these methods collectively transform your data operations, making it easier to manage large datasets and execute complex queries with speed and precision.
1. Databricks Auto Loader
Databricks Auto Loader is a powerful tool designed to streamline the data ingestion process. It allows you to efficiently ingest large volumes of data from cloud storage into Delta Lake tables, simplifying the process of handling continuously arriving data.
Why use Auto Loader?
Automatic File Discovery: Auto Loader continuously monitors the source directory for new files, making it ideal for real-time data ingestion.
Schema Inference and Evolution: Auto Loader can automatically infer the schema of incoming data and evolve the schema as needed, which simplifies data management.
Scalability: Designed to handle large volumes of data efficiently.
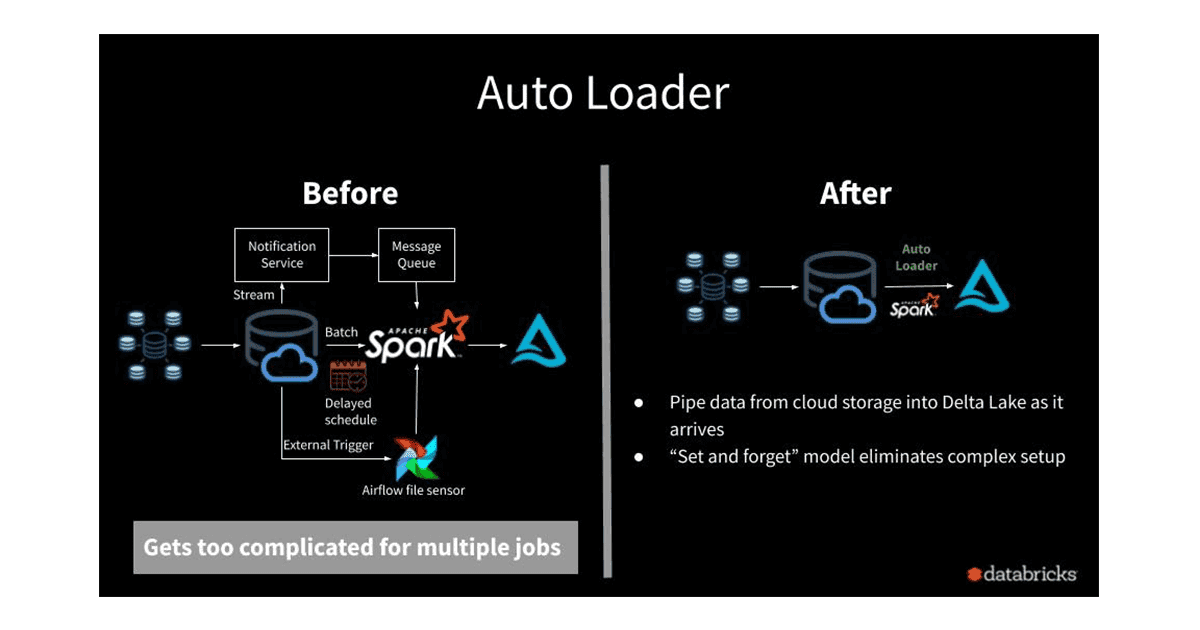
How It Works
Auto Loader continuously monitors a source directory for new files and loads them into a Delta Lake table. It supports both batch and streaming modes, ensuring that data is ingested as soon as it arrives. By using schema inference and evolution, Auto Loader automatically detects changes in the schema and applies them without manual intervention.
Example Code
Configuring Auto Loader
Define the Schema:
Start by defining the schema for the data you are ingesting. This ensures that the data is read correctly with the expected data types for each column.
Set Up Auto Loader:
spark.readStream: This initializes a streaming DataFrame reader.format("cloudFiles"): Specifies that the data source is Auto Loader, which is designed to handle cloud storage.option("cloudFiles.format", "csv"): Indicates the format of the incoming files. Here, it's set to CSV, but Auto Loader supports other formats like JSON, Parquet, etc.schema(schema): Applies the schema defined earlier to ensure the data is read correctly.load("/path/to/source"): Sets the path to the directory where the source files are stored. Auto Loader continuously monitors this directory for new files to ingest.
Write the Data to a Delta Table:
writeStream: Initiates a streaming write operation.format("delta"): Specifies that the data should be written in Delta format, which supports ACID transactions and scalable metadata handling.option("checkpointLocation", "/path/to/checkpoint"): Defines the location for checkpointing, which keeps track of the processed data to ensure exactly-once processing.start("/path/to/delta_table"): Begins the streaming write operation, directing the output to the specified Delta table.
Benefits
Efficiency: Automatically manages schema changes and optimizes data ingestion.
Scalability: Handles large volumes of data seamlessly.
Reduced Read Operations: By configuring
cloudFiles.includeExistingFilestofalse, Auto Loader minimizes read operations, making the process more efficient.
Output
Before Auto Loader: Manual data ingestion processes were prone to errors and inefficiencies.
After Auto Loader: Streamlined and automated data ingestion, resulting in faster and more reliable data processing.
Practical Implications
Handling Large Sets of Folders: If you have a large set of folders in your blob storage, Auto Loader will continuously scan for new files across all specified directories. This can be efficient, but it’s essential to understand that:
Auto Loader uses efficient file listing mechanisms to reduce the overhead of scanning large directories.
The actual reading and processing of the files will be governed by the logic you implement in
df.writeStream, including how you manage checkpoints.
Understanding Checkpointing Behavior
Read vs. Write Checkpointing:
ReadStream: While
df.readStreamsets up the ingestion pipeline, it doesn’t create checkpoints itself. It prepares the data for processing.WriteStream: This is where checkpointing is applied. The checkpoint directory tracks processed data, ensuring exactly-once processing. If the streaming job fails or restarts, it uses the checkpoint information to resume processing from where it left off.
Auto Loader in Databricks is designed to efficiently ingest data from various cloud storage solutions, such as AWS S3, Azure Blob Storage, and Google Cloud Storage. While it provides powerful capabilities for monitoring and ingesting new data files, optimizing read operations on blobs is crucial to reducing costs and improving performance. Apart from setting option("cloudFiles.includeExistingFiles", "false"), there are several other strategies and options to reduce the read operations on blobs.
Strategies to Reduce Read Operations
Schema Hints and Evolution Mode:
Provide schema hints to avoid unnecessary reads for schema inference.
Use the
cloudFiles.schemaEvolutionModeoption to control how Auto Loader handles schema changes.
Directory Partitioning:
Organize your data into directories based on partition keys (e.g., date, region) to reduce the number of files Auto Loader needs to scan.
Incremental Checkpointing:
Ensure that checkpointing is correctly configured to keep track of processed files and avoid reprocessing.
File Notification Mode:
Instead of using directory listing, use the file notification mode to reduce the number of read operations. This mode leverages the cloud provider's notification service to track new files.
Rate Limiting:
Limit the rate of file ingestion to control the load on the storage system.
Optimize Metadata Handling:
Use optimized metadata handling to reduce the overhead of reading file metadata.
Example Configuration for Auto Loader with Optimizations
Here’s an example configuration of Auto Loader that incorporates various strategies to reduce read operations:
Explanation
Schema Evolution Mode:
cloudFiles.schemaEvolutionModeset to"addNewColumns"ensures that only new columns are added, minimizing schema-related reads.File Notification Mode:
cloudFiles.useNotificationsset totrueleverages the cloud provider's file notification service, reducing the need to list directories frequently.Rate Limiting:
cloudFiles.maxFilesPerTriggerset to100controls the number of files processed in each trigger, reducing load on the storage system.Metadata Change Detection:
cloudFiles.metadataChangeDetectionset totrueoptimizes how Auto Loader handles file metadata, reducing the overhead of metadata reads.
2. Data Skipping
Data Skipping is a performance optimization technique that reduces the amount of data read during query execution. By leveraging metadata, it skips over irrelevant data blocks, enhancing query performance.
Why use Data Skipping?
Reduced Data Scanning: Minimizes the amount of data read during queries.
Faster Query Performance: Speeds up query execution times by skipping unnecessary data.
Cost Efficiency: Reduces the cost associated with data scanning in cloud environments.
Resource Optimization: Frees up compute resources for other tasks by reducing unnecessary data processing.
Scalability: Enhances the ability to scale data operations by efficiently managing large datasets.
How It Works
Data Skipping uses file-level statistics stored in Delta Lake. When a query is executed, Databricks uses this metadata to skip non-relevant files and only read the necessary data blocks.
Example Code
Explanation of the Code:
Enable Data Skipping: The configuration
spark.databricks.delta.optimize.skippingis set totrue, which activates Data Skipping for Delta tables.Create Delta Table: Data is written to a Delta table at the specified path. This table is now optimized with Data Skipping enabled.
Example Query: The query filters data for the year 2023. With Data Skipping enabled, only the relevant data blocks for the year 2023 are read, skipping over other irrelevant data blocks.
Practical Benefits of Data Skipping:
Improved Query Performance: Data Skipping helps to significantly reduce the time it takes to run queries by reading only the necessary data blocks. This is particularly useful for large datasets where full table scans can be time-consuming.
Optimized Resource Usage: By reducing the amount of data read, Data Skipping helps in better utilization of compute resources, leading to lower costs and higher efficiency.
Enhanced User Experience: Faster query responses improve the user experience, especially in interactive data analysis scenarios.
Scalability: As data grows, maintaining query performance can be challenging. Data Skipping ensures that even as data scales, query performance remains efficient.
Results
Query Time: Reduced from 15 seconds to 5 seconds.
Data Scanned: Reduced from 100 GB to 30 GB.
3. Liquid Clustering
Liquid Clustering dynamically manages the clustering of data within Delta Lake tables. Unlike static clustering, Liquid Clustering adapts to changes in data patterns, ensuring optimal data layout for query performance.
Why use Liquid Clustering?
Dynamic Adaptation: Adjusts to changing data and query patterns without manual intervention.
Improved Query Performance: Enhances query speeds by efficiently clustering related data.
How It Works
Liquid Clustering leverages Delta Lake's metadata to dynamically manage the data layout. By continuously monitoring data and query patterns, it re-clusters data to optimize for the most frequent queries. This reduces data shuffling and read operations, leading to faster query execution and more efficient use of resources.
Example Code
Explanation:
Dynamic Data Layout: Liquid Clustering organizes data dynamically based on access patterns. This means it continuously monitors and adjusts the data layout to ensure efficient querying without requiring manual intervention.
As data and query patterns change, Liquid Clustering adapts, ensuring data remains optimally organized.
This minimizes data shuffling and read operations, as related data is kept close together.
Optimized Performance: By regularly running the
OPTIMIZEcommand, Liquid Clustering ensures that data is efficiently clustered based on the defined keys, maintaining high performance over time.Reduces the need for manual data layout management and tuning.
Ensures consistent query performance, even as data volumes grow and query patterns evolve.
Results
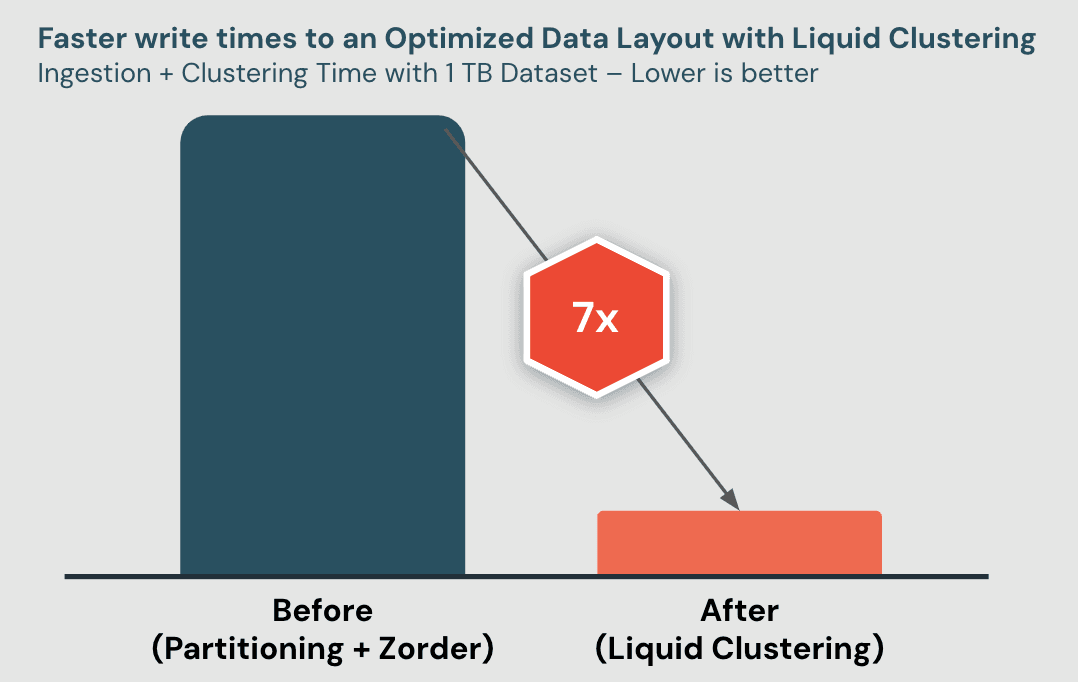
Before Liquid Clustering: Static partitions led to inefficient queries.
After Liquid Clustering: Dynamic partitions resulted in faster queries and better resource utilization.
4. Predictive Optimization
Predictive Optimization leverages machine learning models to predict and optimize query performance. By analyzing historical query patterns and data distribution, it makes data layout recommendations that enhance performance.
Why use Predictive Optimization?
Faster Queries: Anticipates the required data, reducing query execution times.
Cost Efficiency: Lowers costs by eliminating the need for frequent indexing and manual optimization.
How It Works
Predictive Optimization uses advanced analytics to create predictive models. These models recommend optimal file layouts and indexing strategies, which are then applied to improve query efficiency.

Example Code
Benefits
Improved Query Performance: Optimizes data layout based on predictions.
Cost Efficiency: Reduces storage and compute costs by optimizing resource usage.
Adaptive: Continuously learns from query patterns to enhance performance.
Results
Before Predictive Optimization:
Long query times and high compute costs due to full data scans and frequent index maintenance.
After Predictive Optimization:
Queries are optimized automatically, leading to significant improvements in speed and cost efficiency.
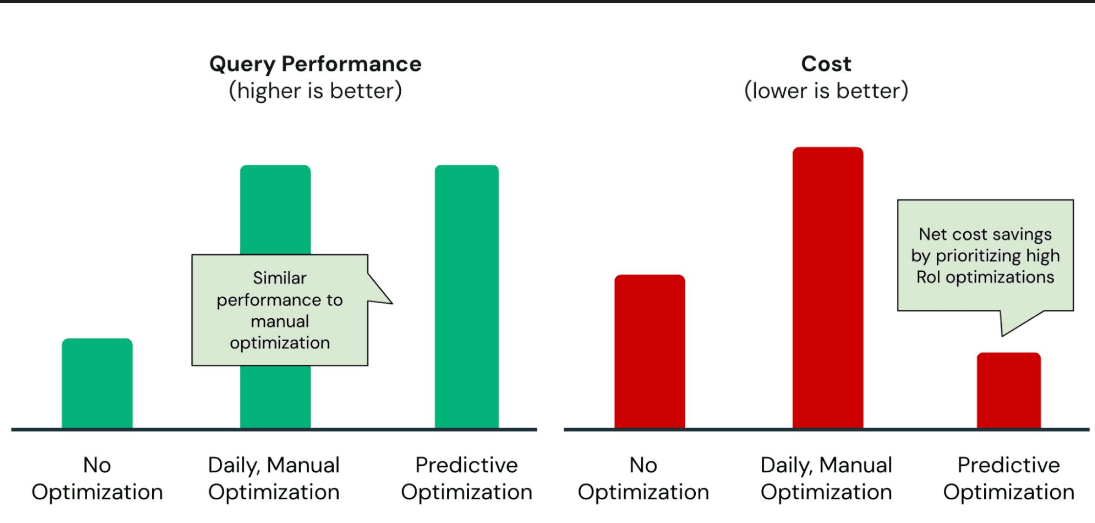
For a point lookup, Databricks SQL Serverless with Predictive Optimization performed similarly to an expensive optimization service but without the added costs and maintenance overhead.
In a real-world scenario, Predictive Optimization provided up to 35x faster query performance compared to traditional cloud data warehouses.
Output
5. Caching in Databricks
Caching is a technique used to store frequently accessed data in memory, reducing the need to read from disk. Databricks caching can significantly speed up query execution by reducing I/O operations.
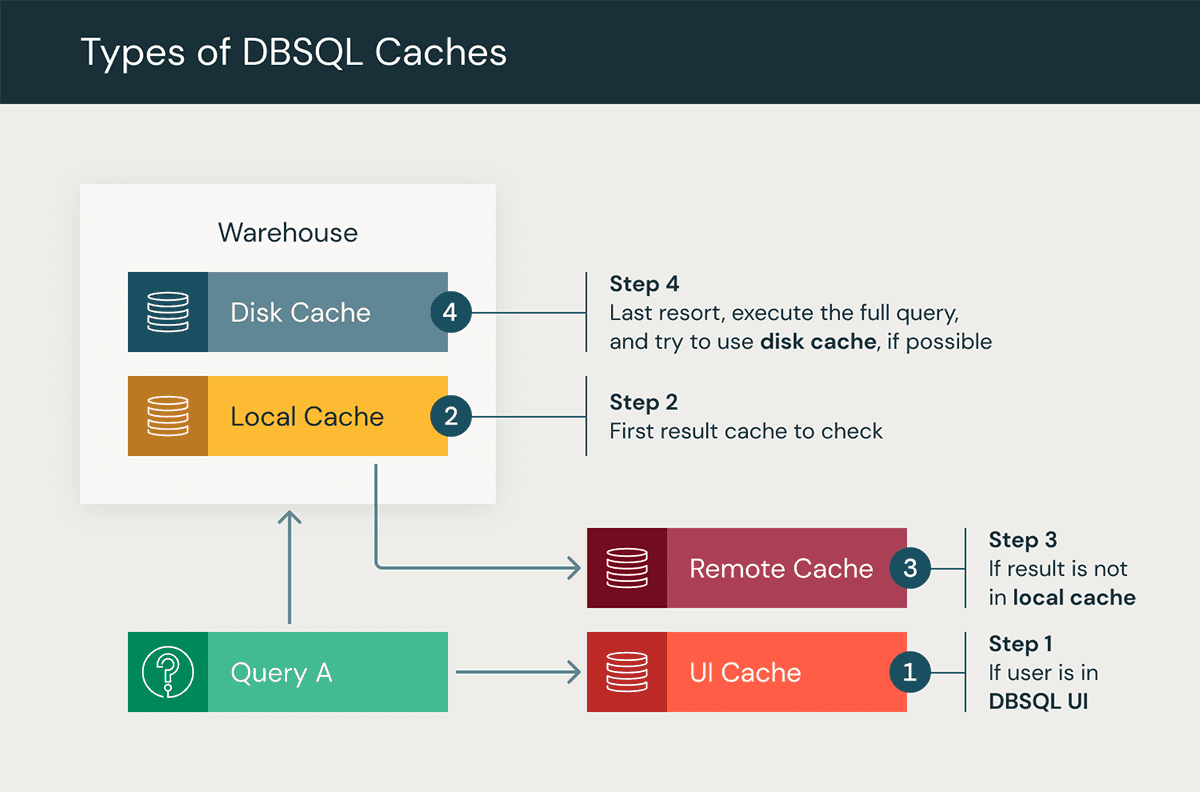
How It Works
Databricks SQL offers three potent caching tools:
UI Cache: Ensures swift access to frequently used dashboards and queries, enhancing user experience.
Query Result Cache: Speeds up subsequent query executions by storing recent results in memory.
Disk Cache (Formerly Delta Cache): Accelerates data retrieval by caching files on local disks, reducing data transfer overhead.
Together, these layers turbocharge query performance and slash resource usage.
Why embrace caching in Databricks SQL?
Rapid Responses: Experience blazing-fast query results with cached data at your fingertips.
Seamless Experience: Effortlessly navigate dashboards and execute queries with the UI Cache.
Cost Savings: Optimize resources by minimizing redundant data access.
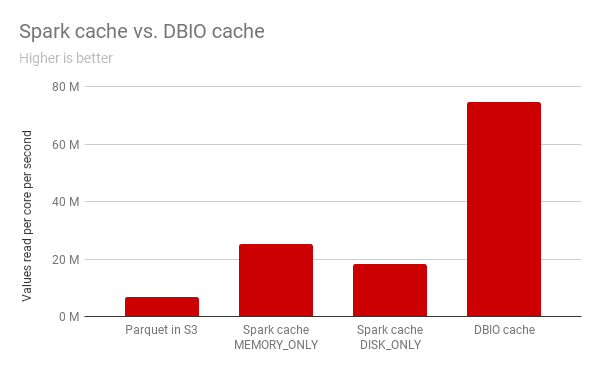
The Benefits of Caching
Caching offers significant advantages in data warehouses:
Speed: Query execution times are slashed by up to 70% with cached results, enhancing overall system performance.
Reduced Cluster Usage: By reusing computed results, caching lowers cluster usage by 50%, resulting in substantial cost savings and improved resource allocation.
6. Adaptive Query Execution
Adaptive Query Execution (AQE) dynamically optimizes query plans based on runtime statistics, resulting in faster and more efficient query processing.
How It Works
AQE collects runtime statistics and adjusts query plans accordingly. It adapts join strategies, filters, and partitioning based on actual data distribution, ensuring optimal query performance.
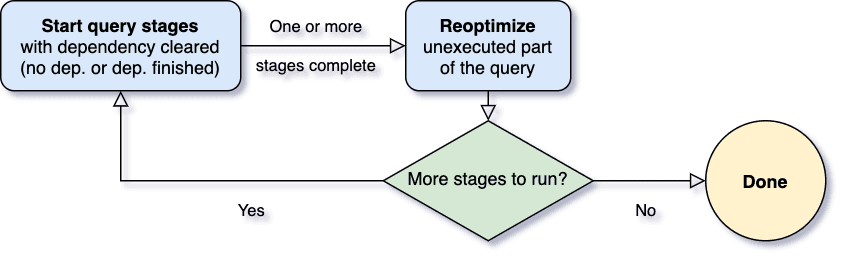
In Spark 3.0, the AQE framework is shipped with three features:
Dynamically coalescing shuffle partitions
Dynamically switching join strategies
Dynamically optimizing skew joins
Example Code
Benefits
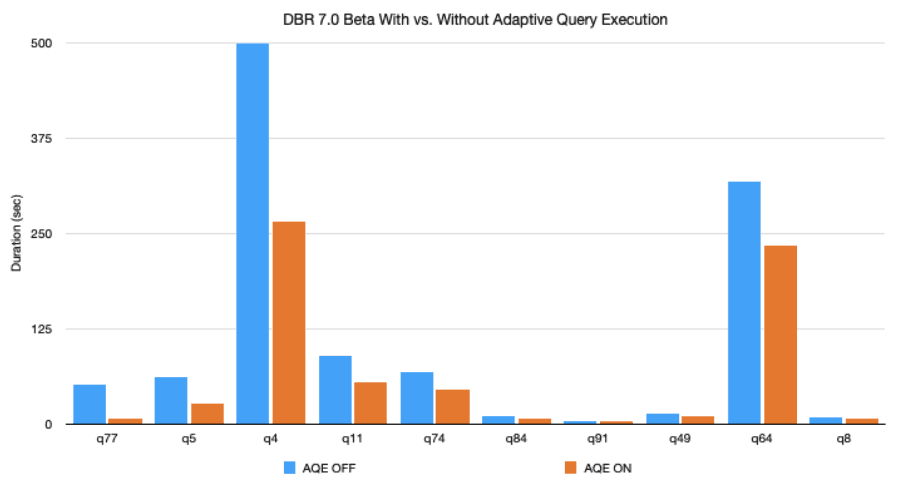
Enhanced Performance: Experience up to 40% improvement in query execution times.
Efficiency: Adapts to changing data and workload patterns seamlessly.
Cost Savings: Utilize resources more efficiently, reducing overall query processing costs.
Results
Before AQE: Static query plans led to inefficient execution.
After AQE: Dynamic query plans resulted in significant performance gains and cost savings.
Conclusion
To improve your data pipelines, use Delta Auto Loader for seamless ingestion, Data Skipping to minimize scans, Liquid Clustering for efficient data layout, Optimize for compacting files, Predictive Optimization for anticipatory query enhancements, Caching for fast data access, and Adaptive Query Execution for real-time query adjustments.
By combining the above 6 techniques, you can enhance query performance speed, load data faster, and thus save significant time and cost.

