


Sep 1, 2024
Materialized Views and Streaming Tables in Databricks SQL
Unveiling Materialized Views and Streaming Tables in Databricks SQL
We're excited to share that Materialized Views and Streaming Tables are now available in Databricks SQL on both AWS and Azure. These features enable seamless, incremental data ingestion from cloud storage and message queues. Materialized Views are automatically and incrementally updated as new data arrives, which makes them perfect for creating efficient, infrastructure-free data pipelines. These capabilities make it easier than ever to deliver fresh data to your business.
In this post, we'll dive deep into how these new features empower analysts and analytics engineers to build and deploy data and analytics applications more effectively within the data warehouse environment.
Challenges in Traditional Data Warehousing
Data warehouses are the central hub for analytics and business intelligence (BI) reporting. However, users often face several challenges:
Self-Service Barriers: SQL analysts frequently depend on additional tools and resources to address data issues, slowing down their ability to meet business needs quickly.
Slow BI Dashboards: When working with large datasets, BI dashboards can be sluggish, making them less interactive and harder to use.
Stale Data: Traditional ETL jobs often run overnight, resulting in dashboards that display outdated information, such as yesterday’s data.
Simplifying Ingestion and Transformation with Databricks SQL
Streaming Tables and Materialized Views empower SQL analysts by integrating best practices from data engineering directly into their workflows. Consider a scenario where you need to continuously ingest and process files arriving in an S3 bucket to create a reporting table. With Databricks SQL, this can be accomplished quickly and easily using just a few lines of code. Here’s how:
1. Discover and Preview Data in S3
2. Ingest Data Continuously
3. Incremental Aggregation Using Materialized Views
Understanding Materialized Views
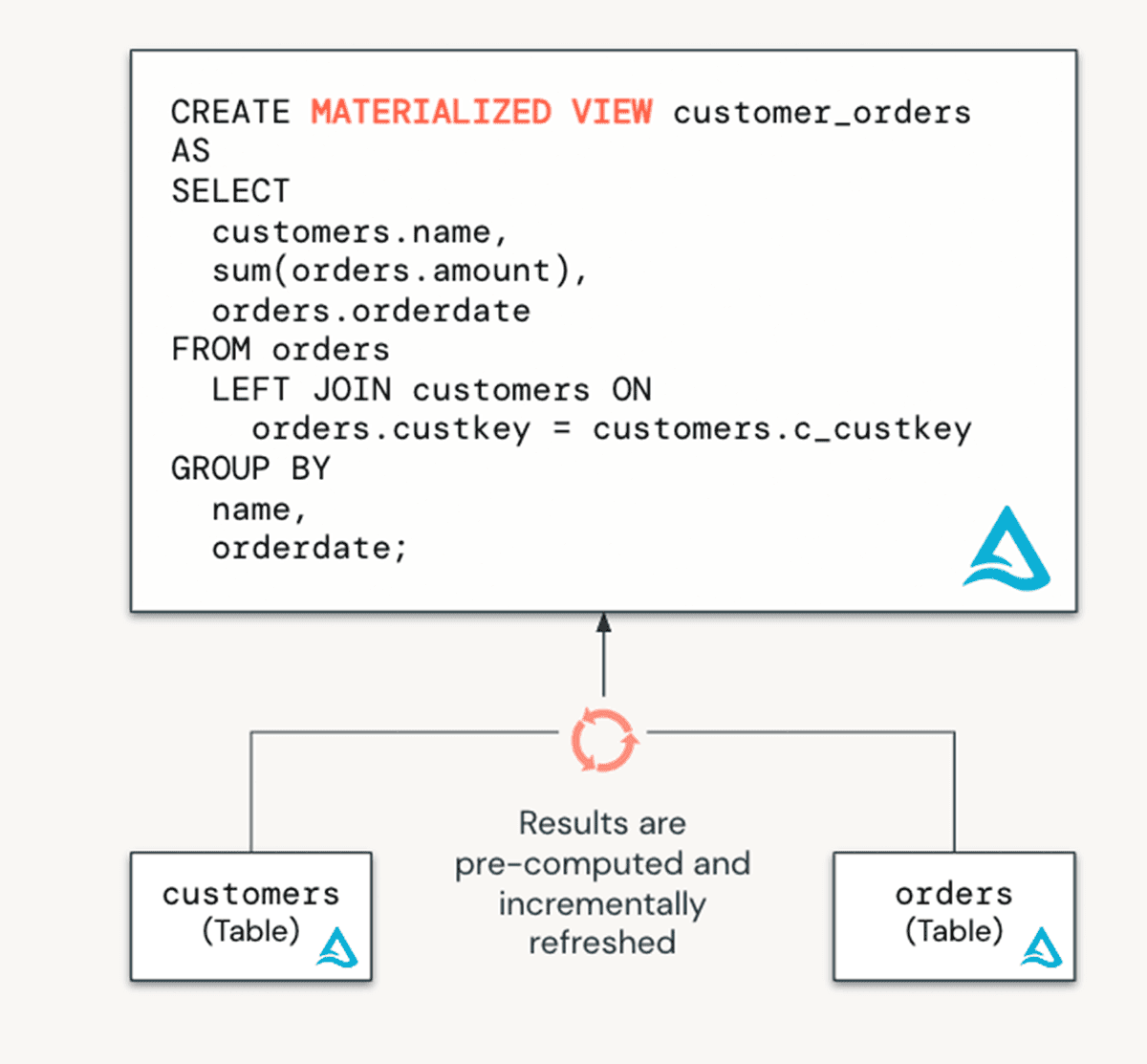
Materialized Views (MVs) are a powerful feature that enhances performance and reduces costs by pre-computing slow queries and frequently used computations. While traditionally associated with data transformation in data engineering, MVs also have immense value in a data warehousing context:
Accelerate BI Dashboards: Precomputed results enable faster query response times, significantly improving the performance of end-user dashboards.
Reduce Data Processing Costs: Since MVs refresh incrementally, there's no need to rebuild the entire view when new data arrives, saving both time and resources.
Enhance Data Access Control: MVs allow for tighter governance, enabling secure sharing of data by controlling access to the underlying base tables.
Built on top of Delta Live Tables, MVs in Databricks SQL provide a robust solution for improving query latency and optimizing data pipelines.
Introducing Streaming Tables in Databricks SQL
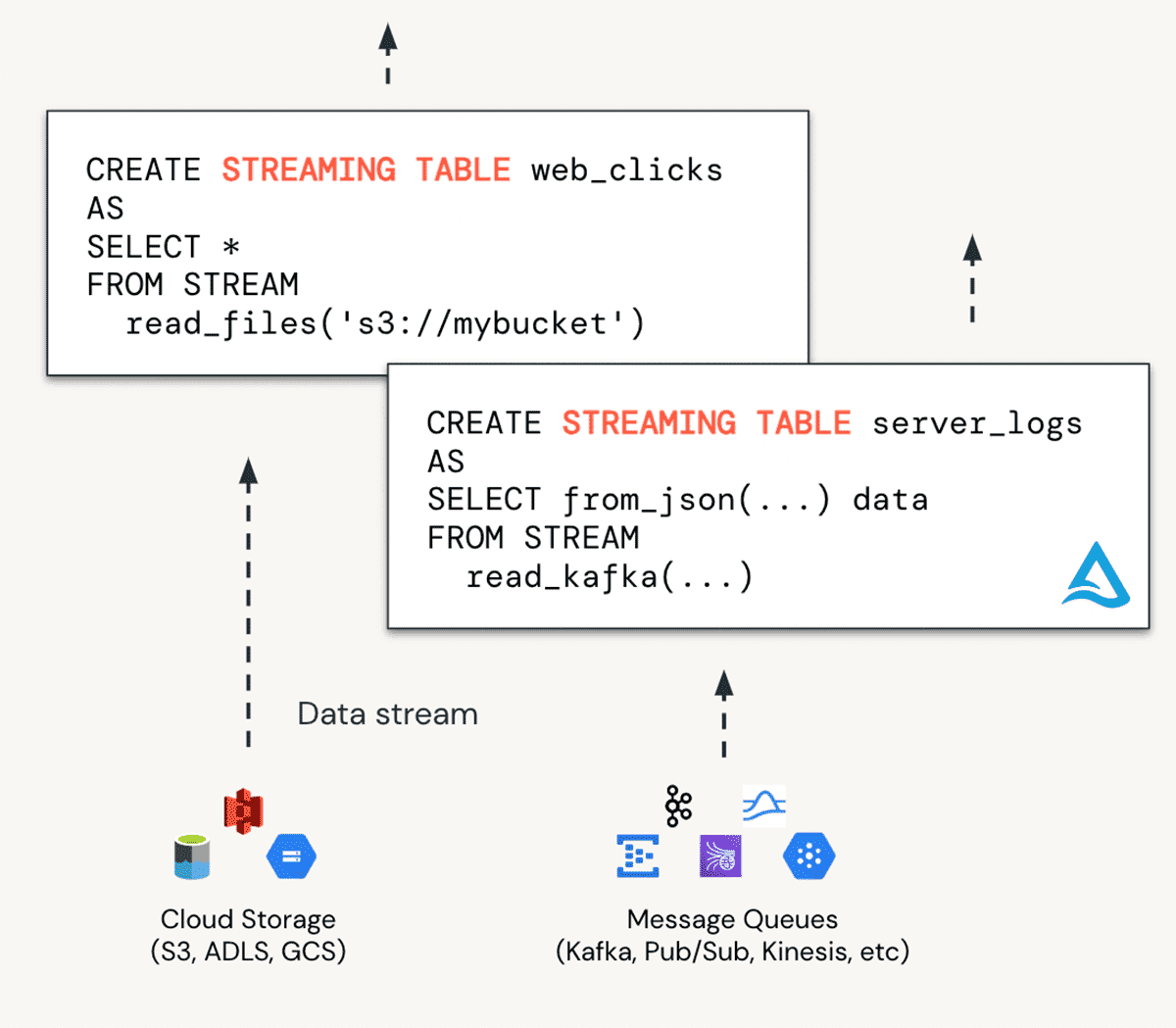
Streaming Tables (STs) are designed to handle real-time data ingestion, making them ideal for populating "bronze" tables with incoming data. STs can continuously ingest data from various sources, including cloud storage and message buses like Apache Kafka and Azure Event Hubs.
Key Benefits of Streaming Tables:
Unlock Real-Time Analytics: STs make it possible to support real-time BI, machine learning, and operational analytics use cases.
Scalability: STs manage high volumes of data more efficiently through incremental processing, avoiding the pitfalls of large batch operations.
Accessibility: With a simple SQL syntax, STs democratize data streaming, making it accessible to a broader range of data practitioners, including analysts who may not have traditional data engineering expertise.
Conclusion: A Unified Approach to Data Engineering and Analytics
Data warehousing and data engineering are essential pillars of any data-driven organization. Yet, managing separate solutions for these functions has traditionally been costly, error-prone, and challenging to maintain. With the introduction of Materialized Views and Streaming Tables in Databricks SQL, Databricks is redefining the way data professionals work.
These new features, combined with the Databricks Lakehouse Platform, empower SQL users to build robust, real-time data pipelines without the need for third-party tools. The integration with partners like dbt further enhances these capabilities, enabling faster insights, real-time analytics, and streamlined workflows.

