


Jun 30, 2024
Efficient Data Management in Databricks: The Power of LCA Chaining, Advanced Error Handling, and SCD Type 2
In the rapidly evolving landscape of data engineering, efficiency and maintainability are paramount. Databricks continues to innovate, offering features that streamline complex workflows and enhance data integrity. We delve into three key features: LCA Chaining, Enhanced Error Handling, and managing SCD Type 2 with Delta Live Tables. Each of these tools addresses common challenges in data processing, aligning under the theme of simplifying complexity and improving reliability in data engineering tasks.
LCA Chaining
What is LCA Chaining and how you can use it to eliminate Complex Subqueries and CTEs
LCA (Lateral Column Alias) Chaining is a new feature introduced by Databricks to simplify SQL queries by eliminating the need for complex subqueries and Common Table Expressions (CTEs). It allows for a more readable and maintainable way to write SQL by referencing previously defined column aliases within the same SELECT clause.
Why Use LCA Chaining?
Simplified Queries: Reduces the need for nested subqueries and multiple CTEs, making SQL queries more concise and easier to understand.
Improved Readability: Enhances the readability of queries by allowing you to reference column aliases directly, without re-specifying complex expressions.
Ease of Maintenance: Makes updating and maintaining SQL code simpler, as changes to calculations or logic can be made in one place.
How Does LCA Chaining Work?
LCA Chaining works by allowing you to create column aliases that can be used within the same SELECT statement, enabling chained references. This means you can define a calculation once and reuse it in subsequent column definitions, simplifying the overall query structure.
Example Use Case
Consider a scenario where you need to calculate multiple metrics based on complex expressions. Without LCA Chaining, you might use nested subqueries or CTEs, making the SQL code verbose and difficult to manage. With LCA Chaining, the same task becomes straightforward and clean.
Example Code:
Without LCA:
With LCA Chaining:
In the LCA Chaining example, you directly reference the increase_percentage_based_on_rating and increase_percentage_based_on_rank columns within the same SELECT statement, eliminating the need for multiple CTEs and making the query more readable.
LCA Chaining is a valuable addition to Databricks SQL, offering a significant quality-of-life improvement for data engineers and analysts. By simplifying query structures and improving readability, LCA Chaining helps you write more maintainable and efficient SQL code.
Enhanced Error Handling in Databricks
Databricks has revolutionized error handling with its structured approach, offering significant improvements over traditional methods. Here are the key differences:
1. Structured Error Classes and SQLSTATEs:
Databricks: Utilizes structured error classes and SQL standard-based SQLSTATEs, providing a consistent and standardized way to identify and categorize errors.
Traditional Methods: Often rely on generic exceptions, making error categorization and understanding more challenging.
2. Human-Readable Error Messages:
Databricks: Designed for clarity, Databricks' error messages are easy to understand, aiding in quick diagnosis and resolution.
Traditional Methods: Error message clarity can vary widely, sometimes leading to confusion and longer resolution times.
3. Programmatic Error Handling:
Databricks: Offers specific methods for handling errors programmatically in Python and Scala, enabling precise and context-aware management of errors.
Traditional Methods: Typically involve catching generic exceptions and handling them based on the error message text, which can be less reliable.
4. Comprehensive Documentation:
Databricks: Provides detailed documentation on error classes and SQLSTATEs, making it easier to troubleshoot and handle specific errors effectively.
Traditional Methods: Documentation quality varies, often lacking the structured support needed for efficient error management.
Example:
In this example:
Error Class Detection: The code checks for a specific error class (
TABLE_OR_VIEW_NOT_FOUND) for precise error handling.Human-Readable Message: Provides a clear, understandable message about the missing table or view.
Programmatic Handling: Allows for specific handling based on the error class, improving code reliability.
Databricks' approach to error handling, with its structured, clear, and programmatically accessible error information, enhances the reliability, clarity, and maintainability of your code.
SCD Type 2 with DLT
Simplifying SCD Type 2 with Delta Live Tables in Databricks
Implementing Slowly Changing Dimensions (SCD) Type 2 can often be complex and time-consuming. Delta Live Tables (DLT) in Databricks offers a simplified approach, making this task much more manageable. Let’s explore how DLT can help you efficiently manage SCD Type 2 updates.
Challenges of SCD Type 2
Complexity in Tracking History: Managing historical data requires tracking changes over time and ensuring accurate historical records.
Handling Inserts, Updates, and Deletes: Each operation (insert, update, delete) must be carefully managed to maintain data integrity.
Sequence and Timestamp Management: Proper sequencing or timestamping is crucial to accurately reflect the timeline of changes.
Solution with Delta Live Tables (DLT)
DLT provides a straightforward way to handle SCD Type 2 updates with simple SQL statements. Here's how you can do it:
Explanation of the Code
Create or Refresh Streaming Table:
This command creates a new streaming table named
targetor refreshes it if it already exists.Apply Changes Into Target Table:
Source Data: The
stream(cdc_data.users)specifies that the changes are applied from thecdc_data.usersstream.Primary Key: The
KEYS (userId)indicates thatuserIdis the primary key for identifying unique records.Delete Operations: The
APPLY AS DELETE WHEN operation = "DELETE"clause specifies that records with theoperationvalue of "DELETE" should be deleted.Sequence by Sequence Number: The
SEQUENCE BY sequenceNumclause ensures changes are applied in the order ofsequenceNum.Exclude Columns: The
COLUMNS * EXCEPT (operation, sequenceNum)clause specifies that all columns exceptoperationandsequenceNumshould be included.SCD Type: The
STORED AS SCD TYPE 2clause indicates that the table is to be stored as an SCD Type 2 table, which keeps historical records of changes.
Example Input Records
Consider the following example dataset for user records:
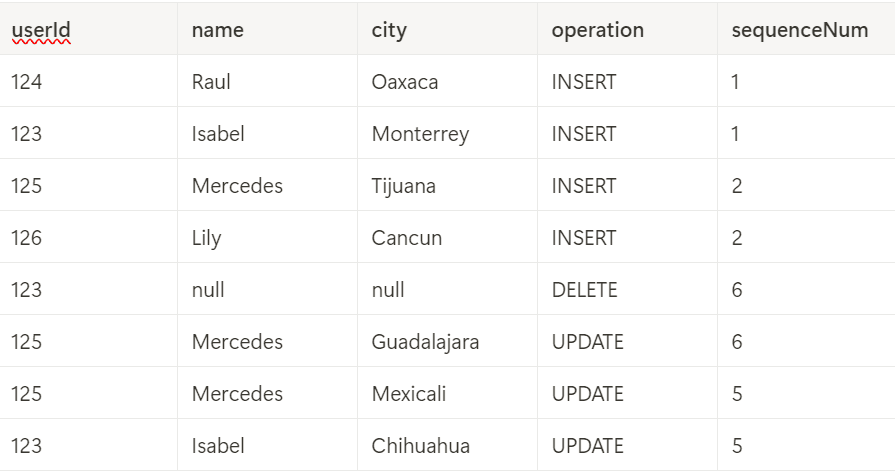
Processing SCD Type 2 Updates
After running the SCD Type 2 example, the target table will contain records with history tracking:
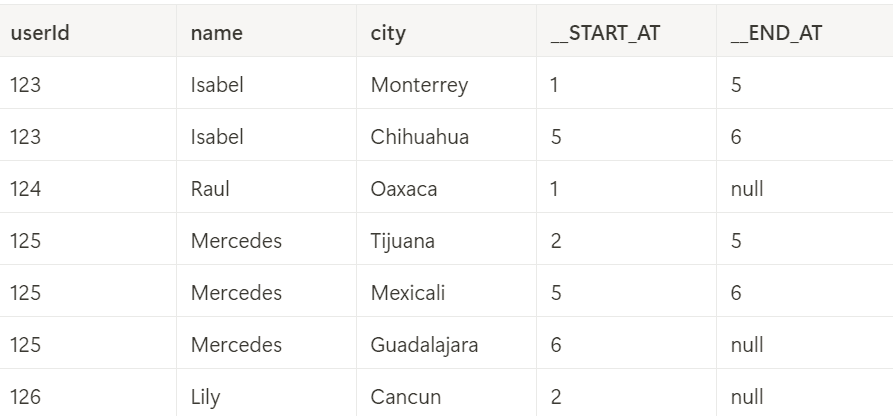
Tracking History on Specific Columns
You can also specify which columns to track for history, excluding others to simplify the table:
After running this example, the target table will exclude city from history tracking:
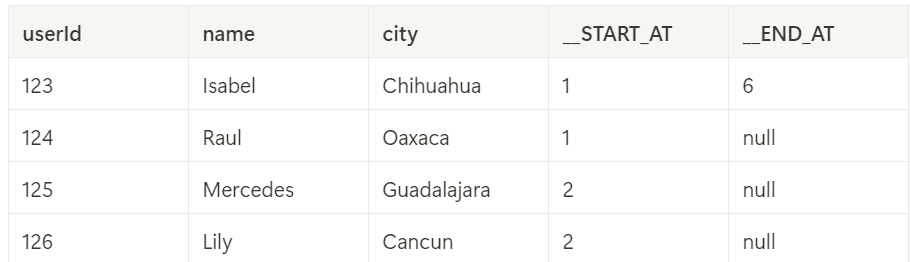
Delta Live Tables (DLT) in Databricks greatly simplifies the process of managing SCD Type 2 updates. With straightforward SQL statements, you can efficiently handle inserts, updates, deletes, and historical tracking. This not only reduces complexity but also ensures data integrity and accurate historical records.
Conclusion
Incorporating LCA Chaining, Enhanced Error Handling, and SCD Type 2 with Delta Live Tables into your Databricks workflows can significantly simplify complex tasks and improve the reliability of your data engineering processes. These features not only enhance query readability and maintainability but also ensure robust error management and accurate historical data tracking.
By leveraging these tools, data engineers can streamline their workflows, reduce complexity, and maintain high data integrity, ultimately leading to more efficient and effective data operations.

