


Sep 8, 2024
Delta UniForm: Seamless Interoperability with Hudi, Iceberg, and Delta Lake
One of the primary challenges in managing data in the open lakehouse is deciding on the optimal storage format. Delta Lake, Apache Iceberg, and Apache Hudi are the three most prominent open formats for building data lakehouses. Each has its advantages, tailored to different use cases like data governance, incremental processing, and time-travel queries. However, organizations often find themselves grappling with the decision of selecting a single format that can meet all their requirements. This is where Delta UniForm (short for Delta Lake Universal Format) comes in.
Delta UniForm bridges the gap between Delta Lake, Iceberg, and Hudi by allowing interoperability across these formats without creating duplicate data. This article explores how Delta UniForm enhances workflows with each format, enabling seamless operations across the three major ecosystems: Apache Hudi, Apache Iceberg, and Delta Lake.
Why Delta UniForm Matters
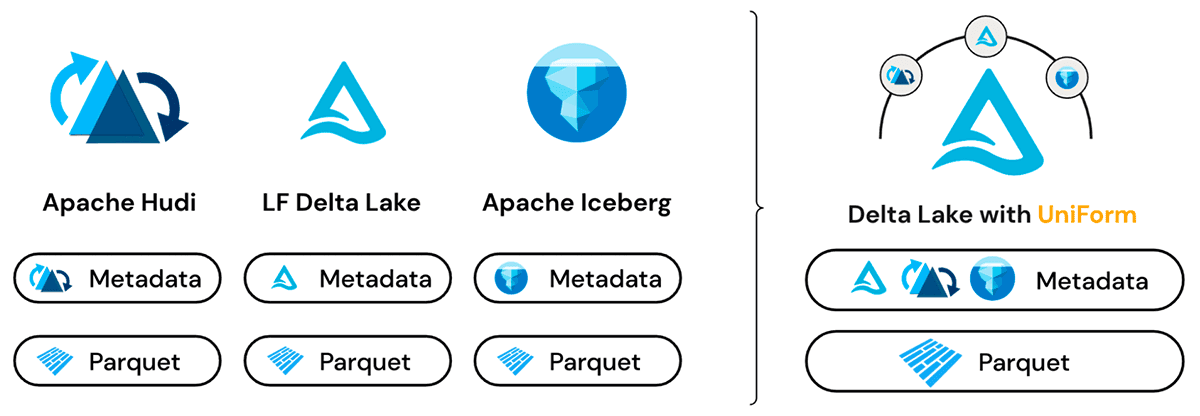
Data lakehouse architectures are evolving to support diverse workloads—batch and streaming analytics, machine learning, and AI. These use cases often require flexibility in accessing data across different engines and ecosystems, where each table format brings its strengths. Delta UniForm ensures that teams can write data once and access it through any of these formats, leveraging the unique advantages of each without creating unnecessary silos or copies of the data.
Delta UniForm offers:
Live metadata synchronization across formats.
Zero data duplication, ensuring no redundant storage.
Automatic metadata generation for Delta Lake, Iceberg, and Hudi.
Interoperability across different engines and workloads.
Let’s dive into the use cases and advantages of using Delta UniForm with each of these formats.
1. Using Delta UniForm with Apache Hudi
Apache Hudi is well-known for its capabilities in providing streaming data ingestion and incremental data updates. With Hudi’s ability to handle upserts and deletes, it’s an excellent choice for managing mutable datasets such as customer profiles, sensor data, and log streams.
Key Use Cases for Delta UniForm with Hudi
a. Stream Processing with Apache Hudi
Apache Hudi shines in streaming use cases where data arrives continuously, and frequent updates or deletes are necessary. Delta UniForm enables data to be written once and then accessed as a Hudi table, benefiting from Hudi’s capabilities for streaming and near-real-time ingestion.
Example: Imagine a financial institution collecting real-time transactions. With Hudi, the incoming data can be processed continuously, and Delta UniForm ensures that the data written is available for processing in both Hudi and Delta Lake/ Iceberg formats. This supports use cases like fraud detection systems, which need to ingest high-frequency data and perform updates without creating separate data pipelines.
b. Incremental Processing
Hudi's ability to capture incremental data changes makes it suitable for Change Data Capture (CDC) scenarios, where only the updated parts of the dataset are read or processed. Delta UniForm enables this feature across Hudi, ensuring that you can incrementally process data and then have the same data accessed as Delta Lake or Iceberg, depending on the workload.
c. Data Lakehouse Governance
Hudi supports time-travel queries, which means you can access past versions of the data for auditing or debugging. Delta UniForm ensures that this functionality remains intact across the formats. For example, you can write data in Delta Lake but access it using Hudi’s time-travel feature for regulatory reporting or historical analysis.
Summary for Hudi:
Optimized for streaming ingestion and incremental updates.
Suitable for CDC and real-time pipelines.
Enables time-travel queries with Delta UniForm handling seamless metadata management.
2. Using Delta UniForm with Apache Iceberg
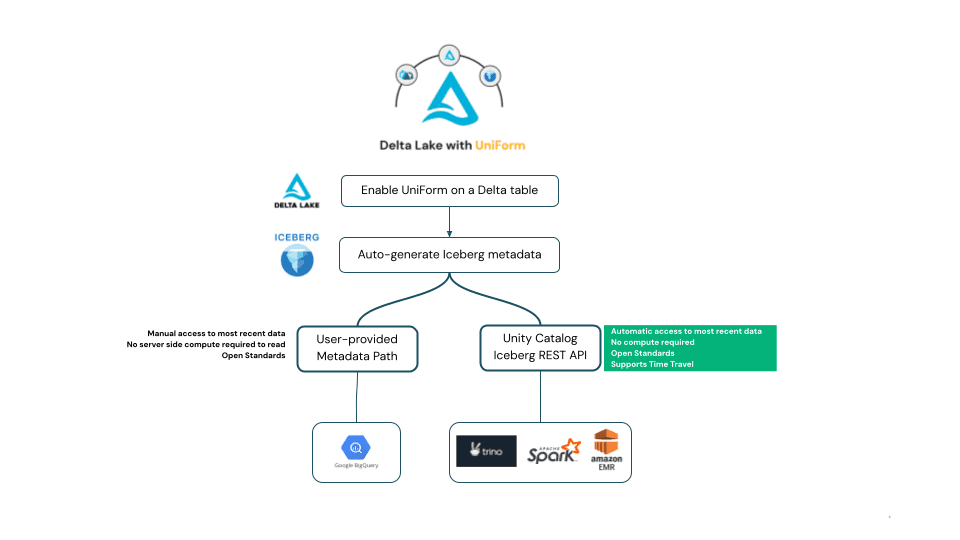
Apache Iceberg is designed with high-performance analytics in mind. It excels in scenarios where scalability and complex querying are essential. Iceberg's strength lies in its ability to handle large-scale analytical workloads with fine-grained partitioning and robust metadata management.
Key Use Cases for Delta UniForm with Iceberg
a. Analytics and Query Performance
Iceberg’s strength lies in its optimized querying for large datasets. It provides efficient partition pruning, schema evolution, and snapshot-based querying, making it ideal for large-scale analytics. With Delta UniForm, you can write data once in Delta Lake and then query it with Iceberg’s optimized query engine.
Example: Consider an e-commerce platform analyzing billions of user interactions. With Delta UniForm, the same dataset can be accessed as an Iceberg table for analytical workloads, taking advantage of Iceberg’s sophisticated indexing and partitioning features, while Delta Lake handles the data ingestion and updates.
b. Schema Evolution
Iceberg allows schema evolution without expensive data migrations. When schemas change, Delta UniForm ensures that the data is still accessible across all formats, without the need for manual interventions or format conversions. This means you can leverage Iceberg’s schema evolution capabilities and still retain interoperability with Delta Lake and Hudi.
c. Snapshot Isolation
Iceberg supports snapshot isolation, allowing readers to view a consistent state of the data even as it’s being updated. Delta UniForm extends this benefit across formats, allowing you to maintain consistent views of data in both Iceberg and Delta Lake. This is particularly beneficial for BI reporting and dashboarding use cases, where data consistency is crucial.
d. Cloud-Native Data Lakes
Iceberg is widely used in cloud-native environments, integrating easily with platforms like Google BigQuery and AWS Athena. Delta UniForm ensures that Iceberg metadata is generated automatically, allowing cloud-native query engines to read the same dataset without additional configuration.
Summary for Iceberg:
Optimized for large-scale analytics with partition pruning and schema evolution.
Supports snapshot isolation, ensuring consistent views of data.
Suitable for cloud-native query engines with automatic metadata generation.
3. Using Delta UniForm with Delta Lake
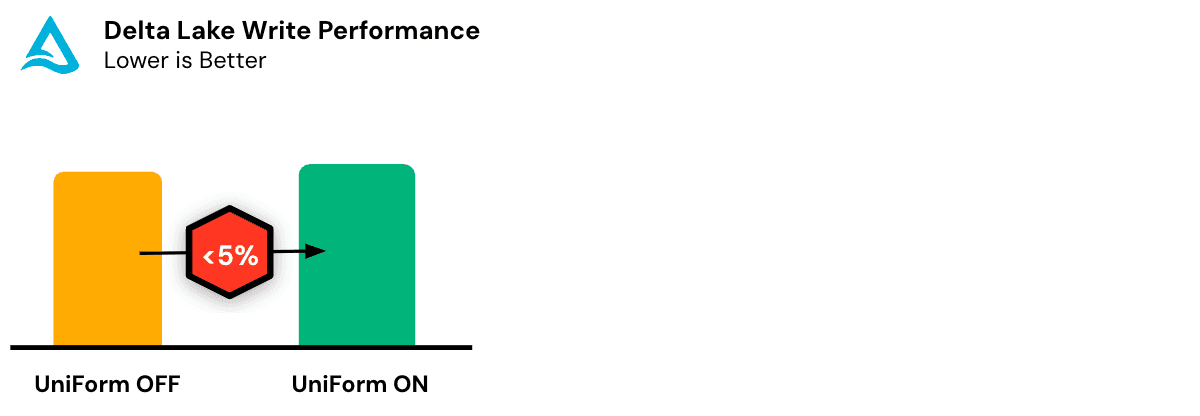
Delta Lake, the foundation of Delta UniForm, is known for its ACID transactions and versioned data management. It’s designed for handling both batch and streaming workloads with reliability, making it a popular choice for building lakehouse architectures.
Key Use Cases for Delta UniForm with Delta Lake
a. Batch and Streaming Unified
Delta Lake enables unified batch and streaming processing. By using Delta UniForm, you can leverage Delta Lake’s transactional guarantees for both real-time and historical data while allowing Iceberg or Hudi to process the same data. This allows teams to maintain a single data source for both streaming and batch processing, minimizing operational complexity.
Example: A media company processing real-time user engagement data can use Delta Lake’s streaming capabilities for ingestion while querying the same dataset in Iceberg for batch analytics. Delta UniForm ensures this interoperability without requiring a separate data copy for each processing engine.
b. ACID Transactions and Data Reliability
Delta Lake’s ACID compliance ensures data integrity in high-concurrency environments. Delta UniForm extends this reliability across formats, so teams can trust that even when writing data as Delta Lake, other systems like Iceberg or Hudi will access consistent, reliable data.
c. Time-Travel and Data Lineage
One of Delta Lake's strongest features is time-travel, which allows users to query previous versions of data. Delta UniForm ensures that the data remains accessible in this way, no matter which format you are querying from. This is particularly valuable for teams needing to audit changes or recover previous states of the data, regardless of the processing engine used.
d. ETL Workflows
Delta Lake's strong ETL support with versioned data means you can easily manage complex data transformation pipelines. Delta UniForm adds flexibility here, as data transformed through Delta Lake can be queried in both Iceberg and Hudi without the need for data duplication or format conversion.
Summary for Delta Lake:
ACID compliance and unified batch/streaming processing.
Enables time-travel and data versioning across formats.
Ideal for ETL workflows and data governance.
Conclusion: A Unified Lakehouse Experience
Delta UniForm eliminates the need to choose between Delta Lake, Apache Iceberg, and Apache Hudi, providing a unified approach that enables organizations to leverage the strengths of each format for different use cases.
For real-time ingestion and incremental processing, Hudi offers the most streamlined workflows.
For large-scale analytics and cloud-native environments, Iceberg excels with its high-performance querying and schema flexibility.
For ACID compliance and batch/streaming unification, Delta Lake leads the way.
With Delta UniForm, the same dataset can be seamlessly accessed across these formats, ensuring flexibility, performance, and governance without the need for multiple data copies. As the lakehouse architecture continues to evolve, Delta UniForm ensures teams can focus on solving business problems without being locked into a single format.
Delta UniForm is available with the preview release of Delta Lake 3.0, enabling teams to take full advantage of a multi-format data lakehouse today.

